好久没写blog了,抽空整理下把最近gc优化的过程以及思路做个记录。gc调优会陷入这样的困境,理论看了一些,但是具体调优的时候参数挨个试,没有具体的思路。 其实理清楚基本的概念,知道参数互相怎么影响,有针对性的进行调整就会有效率多了。
本次调优主要解决的问题的是ygc的问题,不涉及到full gc。
- young gc特别频繁,导致吞吐量不高。吞吐量简单这样计算的,通过gc logs查看最近一次gc到启动的时间,通过jstat查看gc中的耗时算个比例。
- 而且有个别ygc比较耗时,是别的ygc的好几倍。
gc切到了g1,主要是由于是并行-并发,相比CMS没碎片的考虑,而且STW的时间是可预测的。
线上开启gc日志,参数如下:
-verbose:gc -XX:+PrintHeapAtGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintTenuringDistribution -Xloggc:logs/gc.log
Young Gen的大小
在gc log里可以看到如下的日志[GC pause (G1 Evacuation Pause) (young),一般情况就是Eden区满了,触发了Young gc。
g1也是分代回收gc, young gen的大小一般不固定通过NewSize进行配置,而是通过-XX:G1NewSizePercent以及-XX:XX:G1MaxNewSizePercent控制新生代的大小,由gc根据-XX:MaxGCPauseMillis动态进行控制。
动态调整简单理解在剩余内存充足的情况下当满足-XX:MaxGCPauseMillis使用G1MaxNewSizePercent,当不满足的时候使用G1NewSizePercent。
其中默认值G1MaxNewSizePercent=60, G1NewSizePercent=5,需要UnlockExperimentalVMOptions才能配置。
查看默认值可以通过如下命令:
java -XX:+UseG1GC -XX:+PrintFlagsFinal -XX:+UnlockExperimentalVMOptions -version|grep "G1"
Young Gen的分配
g1一样会把young gen分为Eden区以及2个Survivor区(From以及To),其中-XX:SurvivorRatio 指定Eden space与单个Survivor space的大小比例。默认值为8,则Eden区占用8/10, Survivor为1/10。
默认会开启TLAB,对于小对象,g1通过TLAB分配在eden区,大对象会分配在Tenred区。Eden区满了会触发ygc,Eden中存活的对象以及From存活的对象被移动到To中, 存活的对象熬过了一定次数的gc就会被移动到老年代。
这里有几个细节需要注意的:
1) Survivor中最大的gc年龄通过-XX:InitialTenuringThreshold 和 -XX:MaxTenuringThreshold 可以设定晋升到老年代age阀值的初始值和最大值,最大为15。
对象晋升的age会根据-XX:TargetSurvivorRatio动态进行调整,可以通过-XX:+PrintTenuringDistribution查看survivor的分布以及threshold的大小。
2) 在g1中如果存活对象太多,超过了Survivor space的大小,就发生了survivor overflow,会将overflow的数据存在从free space拿的region上,然后放在Tenured区。
如果free space太小没空间可以存储这么多数据,就发生了survivor exhaustion,导致full gc的发生。g1只有ygc以及mixed gc,其中配套的full gc为serial old GC,会严重影响性能。
Young GC频繁怎么处理?
根据分代的理论,ygc主要存储的是临时的对象,比较频繁就是临时对象分配的太快了。
根据服务的qps以及每个请求所需要分配的平均空间大小大致可以算出需要young gc的使用情况。
young gc频繁了就可以降低qps或者减少每个请求的平均空间大小来解决。怎么分流请求就不提了,主要是怎么降低请求的平均空间大小了。
具体而已就是得到请求的对象的分配情况,然后有针对性的减少频繁分配对象的创建。可以通过提供了allocation profiler功能的profiler对jvm进行监控。
一般可以通过visualvm或者jfr,但是visualvm不支持远程jvm的profiler,这里使用的是jmc。
关于jmc,jdk11不再自带jmc,从JMC7开始已经开源,需要独立下载。同时支持sun jdk以及openjdk, 之前版本的jvm需要商业授权使用。
启动jfr有好几种方式,这里是通过jcmd进行启动。
具体的操作步骤
1)开启jfr
jcmd <pid> JFR.start settings=profile maxage=10m maxsize=150m disk=true name=<name>
2)导出jfr文件
jcmd <pid> JFR.dump name=<name>/recording=<num> filename=FILEPATH
3)关闭jfr
jcmd <pid> JFR.stop name=<name>
关于jfr的命令大家可以参考
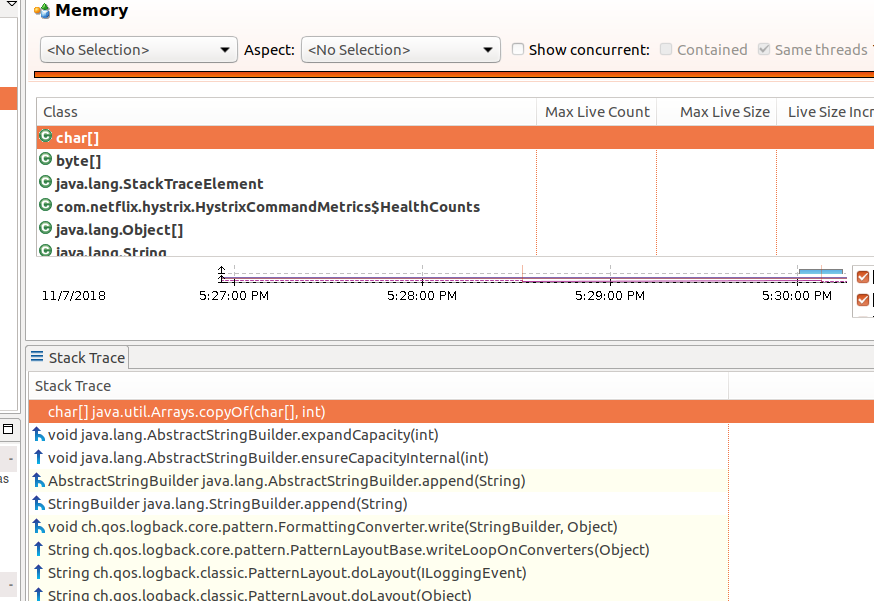
导出jfr记录后可以通过jmc打开,在memory分析里可以查看对象分配的callstack进行具体分析,如下图所示,显示有很多内存是由于日志导致的,是由于部分日志打印的不合理,占用了大量的内存。 把日志调整后,ygc的频次有明显下降。
Young GC的耗时受啥影响?
g1的日志打印的比较详细了,里面打印了ygc每个阶段所执行的步骤以及耗时。
主要有几个时间主要注意
1)Object Copy的处理,这是copy存活对象的时间,主要受live object的影响。
2)Ref Proc/Ref Enq的处理,主要是处理Reference objects以及将引用入队列ReferenceQueues。 其中Ref Proc可以通过设置-XX:+ParallelRefProcEnabled启用并发。
分析后可以看到ygc的耗时主要受live object的影响,与当前具体的young gen的大小无关。
当然如果young gen比较小,对象分配的少,live object也相对会比较少,但是会影响ygc的频率。
live object的大小怎么看呢?
其中在ygc的日志最后会打印survivor的大小变化,例如Survivors: 65.0M->66.0M。
在ygc后,一般eden区会清空,eden以及survivor存活的对象都会copy到 to survivor里,查看最后survivor的大小就是live objects的大小。
live object的回收情况怎么看呢?
eden区的live object在ygc后会在下一次ygc的age 1里,survivor区的live object在下一次ygc里的age+1。例如
刚开始发生gc age 1: 27148352 bytes, 27148352 total
在下一次gc age 2: 23486112 bytes, 30075160 total
age 3: 23433744 bytes, 38232368 total
age 4: 22143864 bytes, 40173376 total
age 5: 18722216 bytes, 58582224 total
age 6: 18096752 bytes, 68430552 total
age 7: 18096368 bytes, 73527672 total
通过对比几次ygc发现,可以观看age的变化,观察survivor区回收的情况。看着随着gc次数的增加,survivor的回收效率逐渐下降了。
通过设置-XX:MaxTenuringThreshold=8,减少对象在survivor区存活的age,使其快速晋级到Tenred区,减少对象copy时间。
有个考虑,调整SurvivorRatio的比例,减少survivor的大小是不是也能满足要求?考虑到减少survivor的大小,可能会提高survivor exhaustion的概率,这里使用的是降低TenuringThreshold。
参考日志如下:
Desired survivor size 100663296 bytes, new threshold 8 (max 8)
- age 1: 10421288 bytes, 10421288 total
- age 2: 7052472 bytes, 17473760 total
- age 3: 20880216 bytes, 38353976 total
- age 4: 3790008 bytes, 42143984 total
- age 5: 75032 bytes, 42219016 total
- age 6: 70952 bytes, 42289968 total
- age 7: 1021760 bytes, 43311728 total
- age 8: 405704 bytes, 43717432 total
, 0.0762263 secs]
[Parallel Time: 52.8 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 149435454.4, Avg: 149435454.4, Max: 149435454.5, Diff: 0.1]
[Ext Root Scanning (ms): Min: 2.7, Avg: 2.9, Max: 3.2, Diff: 0.4, Sum: 11.8]
[Update RS (ms): Min: 12.7, Avg: 12.7, Max: 12.7, Diff: 0.0, Sum: 50.9]
[Processed Buffers: Min: 72, Avg: 82.2, Max: 96, Diff: 24, Sum: 329]
[Scan RS (ms): Min: 0.4, Avg: 0.4, Max: 0.4, Diff: 0.0, Sum: 1.7]
[Code Root Scanning (ms): Min: 0.1, Avg: 0.1, Max: 0.1, Diff: 0.0, Sum: 0.3]
[Object Copy (ms): Min: 36.2, Avg: 36.4, Max: 36.6, Diff: 0.4, Sum: 145.5]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 4]
[GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.3]
[GC Worker Total (ms): Min: 52.6, Avg: 52.7, Max: 52.7, Diff: 0.1, Sum: 210.6]
[GC Worker End (ms): Min: 149435507.1, Avg: 149435507.1, Max: 149435507.1, Diff: 0.1]
[Code Root Fixup: 0.2 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.4 ms]
[Other: 22.8 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 19.5 ms]
[Ref Enq: 0.2 ms]
[Redirty Cards: 0.2 ms]
[Humongous Register: 0.1 ms]
[Humongous Reclaim: 0.2 ms]
[Free CSet: 1.6 ms]
[Eden: 1471.0M(1471.0M)->0.0B(1470.0M) Survivors: 65.0M->66.0M Heap: 1795.5M(2560.0M)->319.5M(2560.0M)]
Heap after GC invocations=557 (full 0):
garbage-first heap total 2621440K, used 327149K [0x0000000720000000, 0x0000000720105000, 0x00000007c0000000)
region size 1024K, 66 young (67584K), 66 survivors (67584K)
Metaspace used 116198K, capacity 126309K, committed 126592K, reserved 1161216K
class space used 13548K, capacity 15194K, committed 15232K, reserved 1048576K
}
[Times: user=0.29 sys=0.00, real=0.08 secs]
参考资料
https://product.hubspot.com/blog/g1gc-fundamentals-lessons-from-taming-garbage-collection
http://tech.meituan.com/g1.html
https://blogs.oracle.com/poonam/understanding-g1-gc-logs
https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
-EOF-


